训练效果越好。=image(图片数量)* repeat(每张图片训练次数)* epoch(训练轮数)*/ batch size(同时训练图片数量)。过大过小的学习率都可能导致训练效果不佳。通常需要通过测试和调整来找到一个合适当训练集的学习率。就可以处理学习越多的训练集的细节。如果训练集的细节越多。

点击启动脚本打开训练器,若刚安装的需要点击国内加速更新一下再点启动脚本
一、路径相关
训练底模
SD-v1-5-pruned-emaonly 或者 ReVAnimated 这种没有被融合过的大模型作为训练用的底层模型

(注:训练SDXL1.0版本的lora出图底模需要和训练底模一致,且不能使用controlnet,并且需要16G的显存才能训练,目前与SD1.5训练结果差别不大)
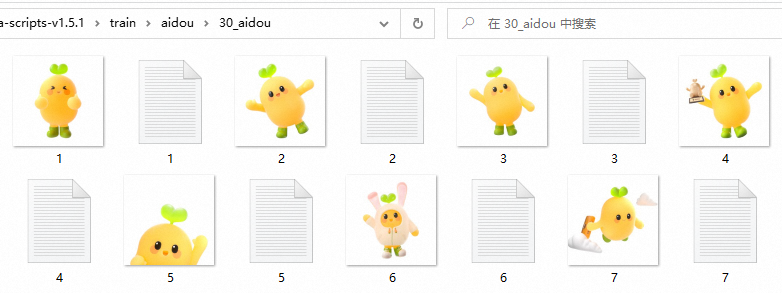
训练集

从训练集角度,训练集图片质量越好,模型效果越好,训练集质量由image+tag决定。
image:近景/远景/不同角度/清晰度
tag:描述全面准确——触发词+背景+视角+动作+光影+镜头构图(自然语言+单词描述)
分辨率

不能超过最大分辨率,但最大分辨率可以调大。训练集尺寸越大,训练效果越好,但是训练时间越长
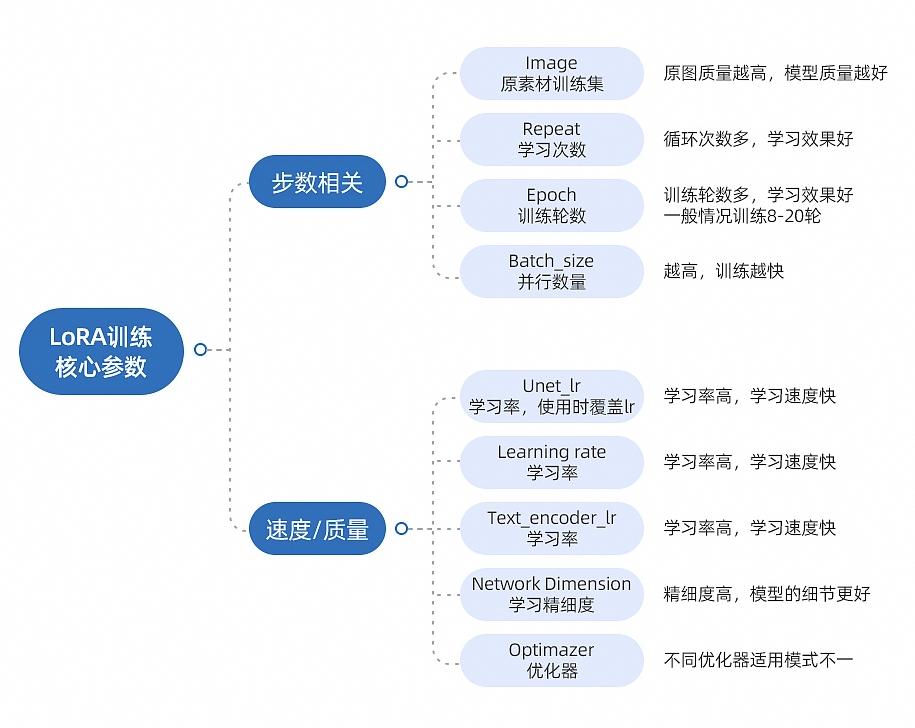
二、步数相关
repeat 每张图片训练次数
代表每张图片循环训练几次,如果训练集较少的情况下,可以增加循环次数,因为训练数据不同,没有具体的标准数值参考,如果觉得学习的不够收敛就增加步数,过拟合就减少次数,但高repeat也会需要更高的算力。
写法:30_aidou,30就是repeat,代表每张图片训练30次

epoch 训练轮次
它和repeat相似,越高对训练的时间越久,也容易导致过拟合,可以提升模型的准确率和效果,但是太高容易炸炉。初步测试建议用10-20,过拟合就减少,收敛不足就增加,看训练集细节程度,假设场景细节多且是大场景,建议开高。

配置高的话,可以开启训练预览图
D:\lora-scripts-v1.5.1\output\sample这个地方出黑图or日志里loss值波动复杂的话就是炸炉了

bath size 同时训练数据量
代表了同时训练的数据量,比如同时训练4张图片。假设训练集一共40张图,一次训练4张,只需要跑10次。

较大的bath size会使训练速度更快,内存占用更大,但收敛的慢(需要更多epoch数)
较小的bath size会使训练速度更慢,内存占用更小,但收敛的快(可以减少epoch数)
对硬件要求比较高,如果硬件好可以开高,默认为1
总训练步数
=image(图片数量)* repeat(每张图片训练次数)* epoch(训练轮数)*/ batch size(同时训练图片数量)
假设一共100张图,每张图训练30次,训练10轮,同时训练1张图,训练步数
=100*30*10/1
=30000 步
三、模型效果相关
unet lr U-Net学习率
学习率是指在机器学习算法中的一个参数,用于控制模型在每次迭代更新时对于权重和位置的调整程度,可以将学习率视为决定每一步跨越多远的因素。
如果学习率较大的时候,每一步更新的幅度就会比较大,模型可能会更快的收敛,但是可能会因为跨越的幅度太大了容易不稳定,可能会出现炸炉或者收敛太快的情况,loss值波动复杂。(学太糙,没学懂)
如果学习率较小的话,过程会比较稳定,就像人走路步子迈太大可能摔倒,迈小一点可能稳当一点,但也可能导致收敛过慢来不及,达不到最佳收敛效果,loss值波动比较平稳。(学太慢,没学到)
所以选择合适的学习率非常重要,过大过小的学习率都可能导致训练效果不佳,通常需要通过测试和调整来找到一个合适当训练集的学习率,以达到更好的模型效果。
选择合适的学习率相当于选择一个合适的节奏,稳步前进,但是如果过小的话这个训练过程时间会比较长。

(如果开启U-Net学习率就只用管红色框里的,蓝色不用管)
1e-4=1/10000=0.0001
1e-5=1/100000=0.00001
1e-4/10=1e-5
1e-4/ 2 =5e-5
text_encoder_lr一般是Unet lr的十分之一或二分之一左右
新手可用默认
optimizer 优化器
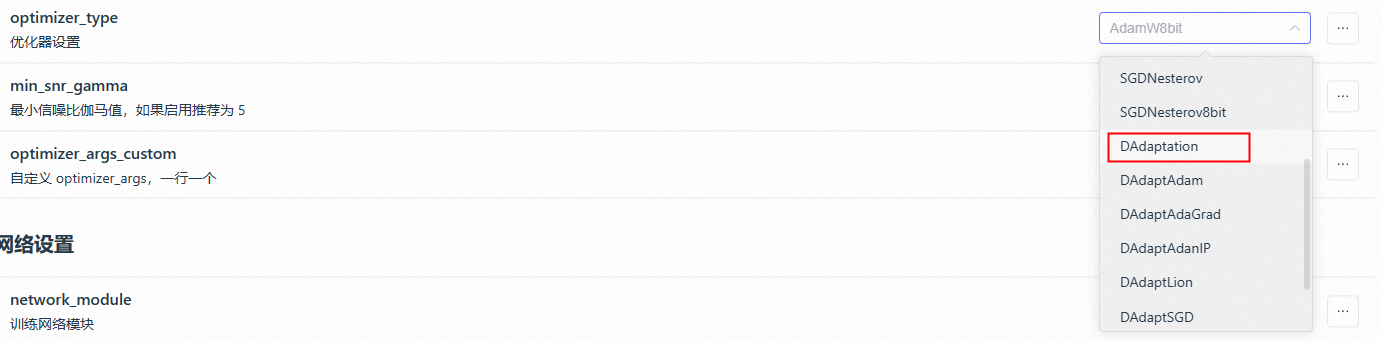
主流使用的是AdamW8bit\DAd\Lion\神童优化器这几个,其中DA是一个自适应学习率的优化器
这里DAdaptation优化器一般用于测试一组素材的最优学习率
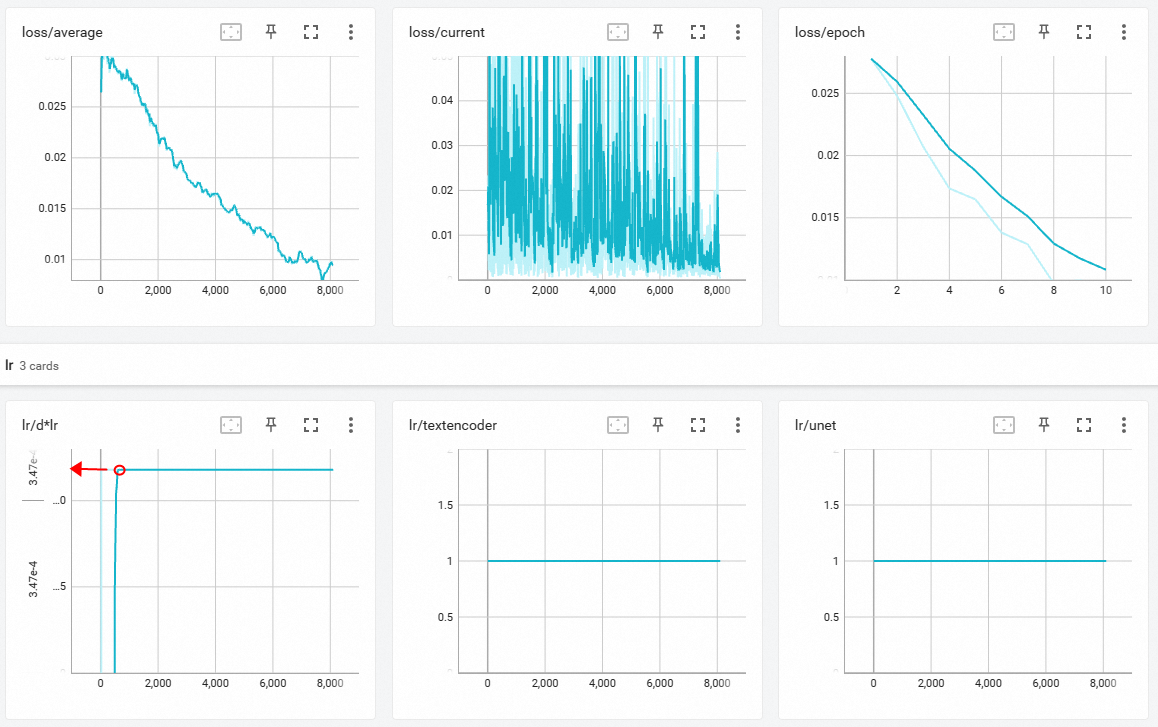
如何利用DA优化器寻找一个最优的学习率
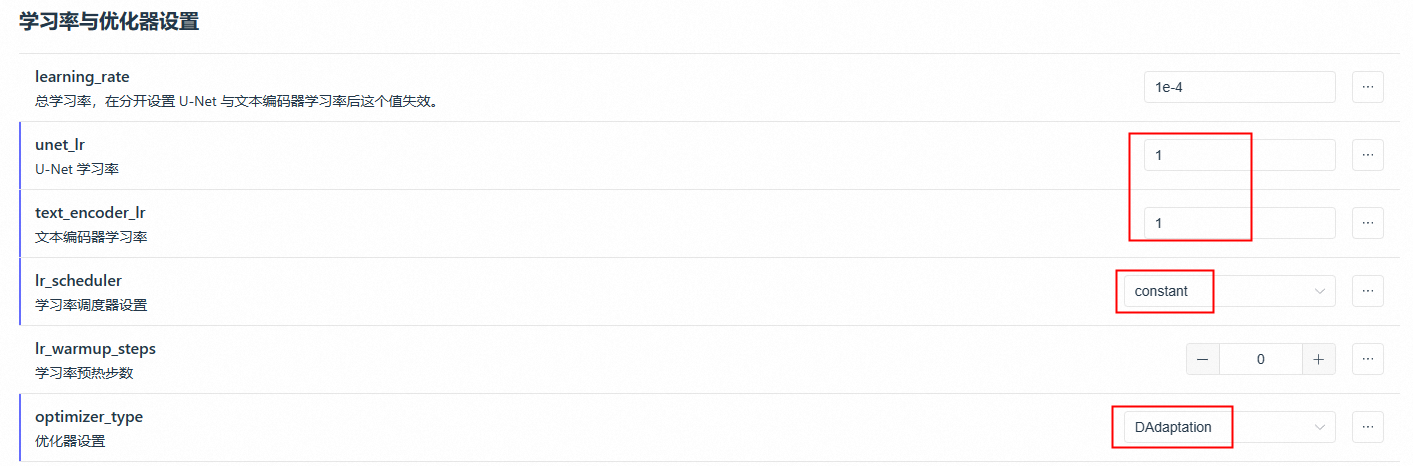
01-将DA优化器的Unet设为1,text_encoder_lr设为1,调度器为constant
02-其他参数按照正常训练流程设置即可,然后就可以点击训练了
03-日志里的第二排第一个折线图tensorboard上升达到一个值后就会恒定不变,这个值就是最优unet_lr学习率
04-然后就可以用这个最优学习率去选择优化器里的Lion或者AdamW8it进行训练,使用Lion需要最优学习率➗3
dim 网络维度
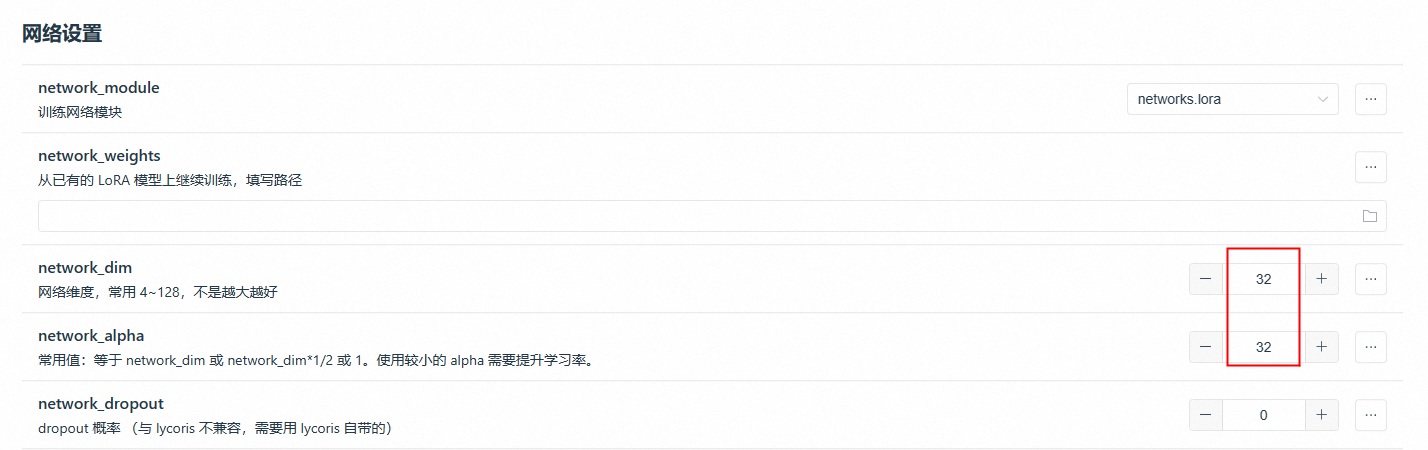
network_alpha常采用与network_dim相同值或者一半,不能超过network_dim的值
network_dim“网络维度”指的是神经网络模型中的参数数量或网络层数,可以理解为规模复杂性,更多的神经元可以学习更加复杂的元素。而network_alpha“超参数”用于控制模型的复杂性。
可以理解为,越大的dim,就可以处理学习越多的训练集的细节,如果训练集的细节越多,则dim就需要相对调大,而aplpha越小则越约束模型,避免过拟合,但也不可以太小,太小会出现下溢,影响模型效果,而且速度也会变慢。
大场景+细节较多,dim:128 看效果适当降低 IP或者细节比较少的图 dim:32、64 根据具体情况调整测试
(细节多的训练集可以开高dim和epoch训练轮次)
(如果unet lr U-Net学习率小,network_alpha也小,可能会导致太慢达不到好的模型效果)
过拟合(步数太多,学过头)
降低 训练集张数、 repeat(每张图片训练次数)、 epoch(训练轮数)、network_dim(网络维度)、network_alpha(超参数), 或者增加batch size(同时训练图片数量)
欠拟合(步数太少,没学到)
增加 训练集张数、repeat(每张图片训练次数)、 epoch(训练轮数)、network_dim(网络维度)、network_alpha(超参数),或者降低batch size(同时训练图片数量)